Your Data Is Free Now. Your Meaning Is the Lock-In.
Quick Answer
Every major platform converged on a context layer, and that is where lock-in now lives. Snowflake, Databricks, AWS, Microsoft, and SAP all shipped meaning layers in 2026, relocating vendor lock-in from storage to semantics.
Business meaning such as definitions, ontologies, and governance does not travel inside a Parquet file. Open table formats freed the bytes, but the business context that makes data useful remains trapped inside each platform's engine.
You are paying on two meters simultaneously and you funded the lock-in yourself. Every context lookup burns token spend and platform compute at once, and the meaning was auto-built on your dime inside their control plane.
Every major platform shipped a context layer this year. The bytes finally travel anywhere. Your business meaning does not, and that is exactly where you get held, and where the bill is quietly going.
I spend my weeks with two kinds of leaders. The data leaders bolting AI onto a foundation that was never built to hold it, watching it stall. And the leaders handed an AI mandate who have never once had to think about the data underneath them. Different chairs, same result. The invoice climbs every month and the value never arrives.
You can see it in the numbers most people are too polite to say out loud. The most cited enterprise study of the year found that the large majority of AI pilots produced no measurable return, and the reason was almost never the model. The systems simply did not understand the business they were supposed to serve. At the same time the spend keeps compounding. Gartner now has worldwide AI spending crossing two and a half trillion dollars this year. So we have the most expensive technology wave in a generation landing on the thinnest results anyone has seen, and the space between those two facts is the most important thing happening in enterprise data right now.
The reason is not the model. It is not the effort either. The meaning got left behind. And the platforms just spent their biggest launches of the year proving it.
Everyone built the same thing in the same quarter
If you only read the headlines from this year's summits, you saw a hundred separate product launches and a lot of noise about agents. Read them together and the noise resolves into a single, almost startling agreement. Every major platform built a context layer.

Five companies with different origins, building the same capability in the same season.
Snowflake shipped Horizon Context and Cortex Sense. Databricks shipped Genie and Unity Catalog Semantics. AWS shipped Context, a knowledge graph that grounds agents in governed data. Microsoft has Fabric IQ doing the same across its lake. SAP is leaning on the business logic it has authored for fifty years. Five companies with wildly different origins and philosophies, building the same capability, in the same season, and spending their flagship keynotes on it.
When competitors who agree on nothing else suddenly converge on one thing, that is not a coincidence and it is not a fad. It is the market telling you where the value moved. For a decade the fight was about storage and compute. This year the fight quietly relocated to the layer that sits on top of the data and tells the machine what the data actually means. That relocation is the whole story, and almost nobody is pricing it correctly.
Give the silo war its due, because we won it
Start with the genuinely good news, because it is real and it earned. For years the entire industry fought to get data out of its silos, and we more or less won that war. Apache Iceberg became the common table format, so your data is no longer trapped in one vendor's proprietary storage. The warehouses learned to read each other's catalogs. Zero-copy sharing retired whole categories of pipelines that used to exist only to move bytes from one place to another. And the Model Context Protocol gave agents a standard doorway into the systems where work actually happens.
Add it up and your data is more portable today than it has ever been. You can keep it in an open format, leave it where it lives, and let almost any engine reach it without copying or rewriting a thing. If the entire game were moving data from one place to another, we could declare victory and go home.
We cannot, and the reason is the part the launch coverage skips entirely.
Moving the data is not the same as moving what it means
A table is just rows and columns until someone tells you what the columns mean. A file full of numbers does not know that your fiscal year starts in February. It does not know that revenue excludes intercompany sales, or that a customer does not count until the contract is signed, or which of your six competing definitions of an active user is the one the board actually sees on the slide. All of that, the business meaning that turns raw data into something a person or an agent can reason about, lives in a separate layer entirely. And that layer does not travel inside a Parquet file.
A way to picture it. Think of your open data as a pile of words, perfectly portable, that you can ship anywhere. Context is the dictionary that tells you what those words mean in your business. You can hand someone every word you own, but without the dictionary they cannot read a single sentence. The data got standardized. The dictionary did not, and that is the layer this whole article is about.
This is the layer every platform just built. And here is the thing that should stop a value engineering leader cold: they are building it out of your own data, automatically, and you are paying for the privilege. More on that meter later. First, how they build it, because the how is where the lock-in hides.
How the platforms build your context
Each platform constructs that meaning a slightly different way, but the move is the same: read everything around your data and assemble a model of what your business means.
Databricks calls its version Genie. It learns continuously from your tables, your past queries, your dashboards, your pipelines, and the apps you have connected to it, and it assembles a living picture of how your business fits together. It even ranks competing definitions by a kind of authority score, so the metric that is used most and trusted most rises to the top.
Snowflake calls its version Horizon Context, paired with Cortex Sense. It reads your schemas, your query history, your lineage, your dbt models, and your BI tools, and instead of caching one static model it assembles the right context the moment an agent asks a question. Snowflake also keeps a deliberate split: people curate and govern the definitions, and the runtime engine serves them to agents.
AWS shipped Context, which maps the relationships across your governed data into a knowledge graph and lets agents search it at query time. It routes the inferred relationships through human data stewards who promote them to production before any agent is allowed to trust them.
Microsoft's Fabric IQ does the same over OneLake, and it can bootstrap from the Power BI semantic models many enterprises already have. SAP takes the opposite road entirely. It does not need to infer meaning from metadata because it already authored that meaning across fifty years as the system of record, so it hands the definitions down from the top.
Notice what every one of them quietly admits. Each keeps a human in the loop. Snowflake curates. Databricks pairs its automation with an annotated glossary. AWS routes through stewards. They all know the same uncomfortable truth: the machine can draft the meaning, but a person still has to decide which revenue number is the official one. That decision has never been a technology problem. It is a political one, and it is the part of this work that has been hard since long before any of this. I call the cost of that decision the reconciliation tax. Most companies have paid it for years without naming it, in the merger that never fully integrated, in the five teams with five versions of one metric, in the dashboard nobody quite trusts. AI does not remove that tax. It makes it urgent, because now an agent will act on whichever definition it was handed, confidently, at machine speed.
The model was never the bottleneck
I want to say something plainly, as someone who has spent his career on the data side of this rather than the model side. The model is not the hard part anymore, and you do not have to take my word for it. The vendors proved it with their own benchmarks, almost against their own marketing instinct.
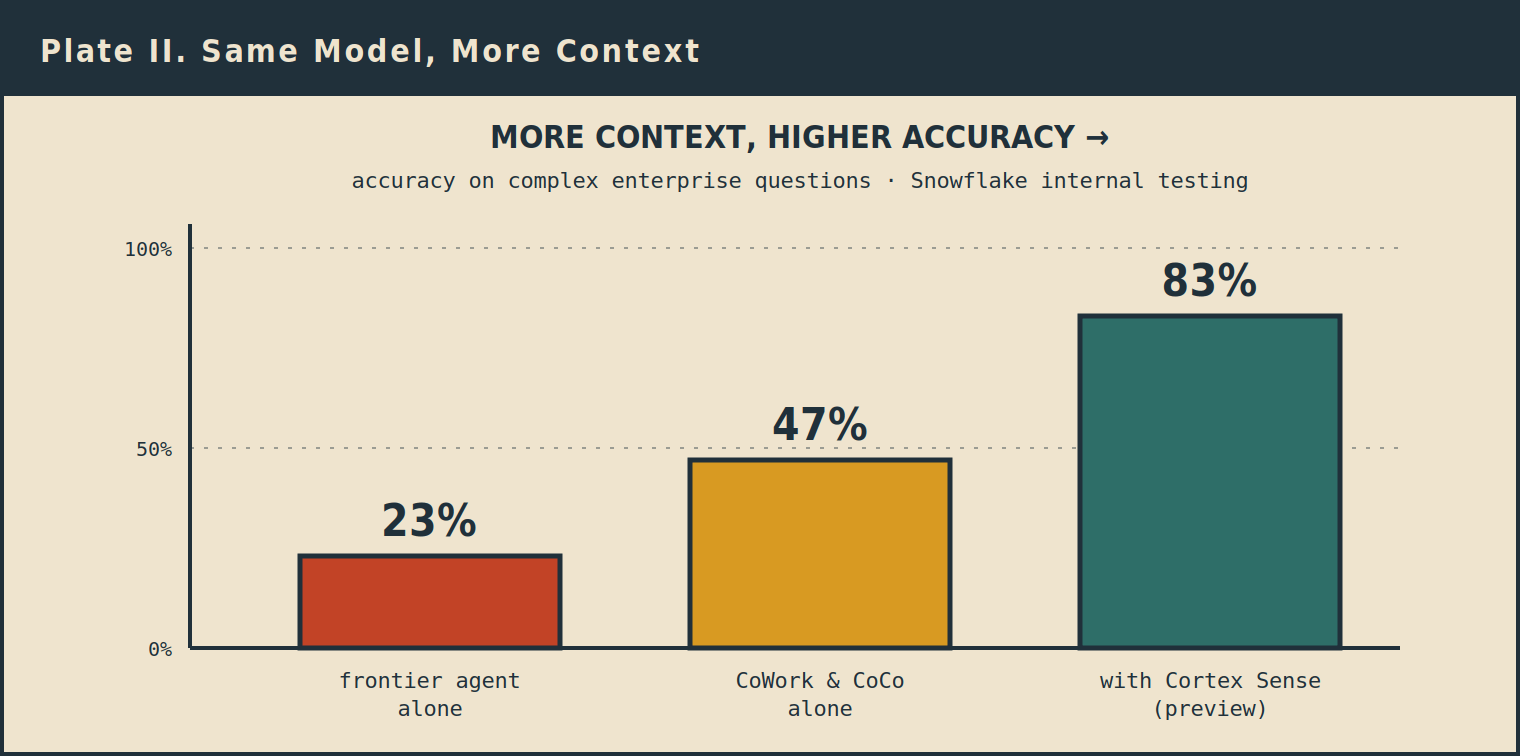
Snowflake's own testing: the same agents climb from 23% to 83% as more governed context is switched on. Cortex Sense was in private preview, so treat 83% as a near-future figure.
Snowflake put real numbers on it, from its own internal testing on complex enterprise questions. A frontier coding agent reaching into Snowflake with just the standard connector answered 23 percent of them correctly. Snowflake's own CoWork and CoCo agents, which sit inside the platform's governance, reached 47 percent. Turn on Cortex Sense, the layer that assembles the business context at runtime, and the same agents hit 83 percent. Databricks reported a similar jump with its Genie Ontology, 52.4 percent for the strongest general-purpose coding agent against 84.5 percent for Genie. One honest caveat: these are vendor numbers measured on their own test sets, and Cortex Sense was in private preview when Snowflake published that 83 percent, so treat it as a near-future figure rather than today's shipping product.
Read those numbers and the conclusion is hard to avoid. What separated the worst result from the best was not a smarter model. It was more business context. Frontier intelligence is becoming abundant and close to interchangeable. What separates a system you can trust from an expensive demo is the meaning you feed it. So when a vendor tells you the differentiator is their model, be skeptical. The differentiator is the context, and the real question is who controls it.
What that context is actually made of
If context is the prize, it is worth being precise about what sits inside it, because not all of it carries equal weight. Two parts do the heavy lifting.
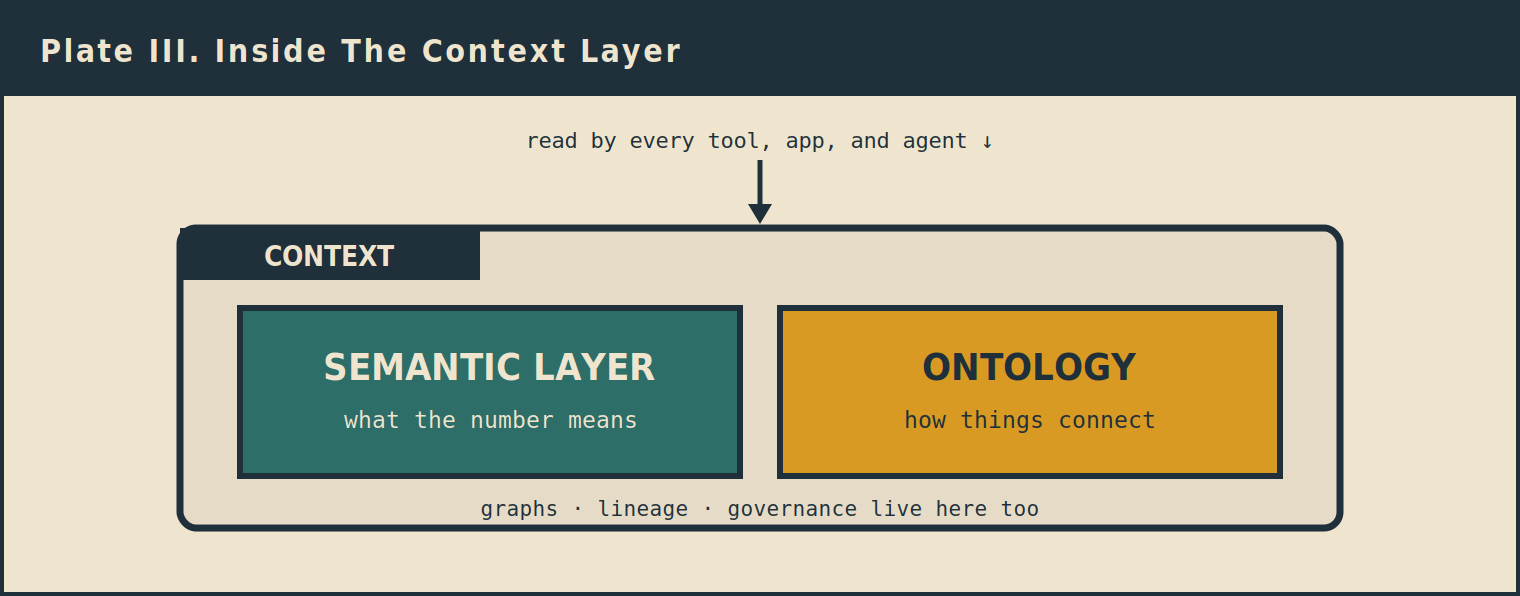
The two parts that carry the weight: what the numbers mean, and how they connect.
The first is the semantic layer. This is the governed set of definitions, the authoritative answer to what a number actually is, so that revenue means the same thing on Tuesday that it meant on Monday no matter which tool or agent asks. Everything else depends on this, because a relationship built on a wrong number is just a confident wrong answer delivered faster.
The second is the ontology. This is the map of how things connect: that a customer is a kind of account, that an order ties to a product through a line item, so an agent can reason across the business instead of looking up one isolated fact at a time. Graphs, lineage, and governance live alongside these too, but the semantic layer and the ontology are the two pieces that decide whether the rest is worth anything. Get the definitions right and the relationships right, and you have something an agent can actually be trusted with. Get them wrong, and a better model just helps you be wrong at scale.
The lock-in moved to the context layer
Now the turn, and it is the entire point of this piece. The platforms build that context beautifully. But the context only works inside their house.

Storage and compute opened up, and you won that. The lock simply moved one floor higher.
You can take your data anywhere. Iceberg made sure of that, and it is genuinely yours to move. But the moment you want to use the meaning, you come back to their platform. The definitions run through their engine. The governance is enforced at their catalog. The ontology and the agent identities live in their control plane. If you have to return to the platform to use your own meaning, and you are pushed to lean on the rest of their stack to do it, that is the lock-in. Plainly. No marketing language required.
So say it without flinching. The lock-in moved to the context layer. It used to live in storage and compute, and that fight is over, and the customer mostly won it. It moved up one level, into the meaning. An open table format is not the same as open meaning. The bytes are free to roam. The understanding that makes the bytes useful is not.
And the cruel part is that the understanding is the expensive part. The data was always replaceable. You can copy it, move it, regenerate it. Your business meaning is the thing you cannot easily rebuild, because it took years of human argument to settle and it encodes how your specific company actually works. That is precisely the asset that just got welded to one vendor's engine.
So where should your context live?
Once you accept that the lock-in moved to the context layer, the real question gets simple and a little uncomfortable. There are only three places your context can live, and they are not equal.

Three places to put your context. Only the independent layer lets meaning travel across every source and model.
It can live inside the model. This is the wrong layer, and it is worth being clear about why, because a lot of early AI projects started right here. You feed your business meaning into the prompt, and it burns tokens on every single call. The context window is finite, so it does not scale to the breadth of a real enterprise. It is ungoverned, with no lineage, no access control, and no human who ever decided that this definition was the official one. And worst of all, it chains your meaning to one model. The whole point of an open AI strategy is to pick the best model this year and a different one next year. If your context is engineered into a single model, you redo that work every time you switch, so you either overpay forever or you quietly stop switching. Your meaning should outlive any model you happen to be running this quarter.
It can live inside the data platform. This is governed and genuinely powerful, and for some companies it is the right answer. But it is structurally caged, for three reasons. First, it is bound to one engine. A semantic view defined in Snowflake runs in Snowflake. Databricks metric views run in Databricks. The definition does not port. So if you run both, and most large enterprises do, you define revenue twice and the two slowly drift apart. Second, it only sees its own data. The platform builds meaning out of the data and metadata it holds, so it cannot author governed meaning across SAP, Salesforce, Oracle, and the files sitting outside it, except through partial federation. Third, its incentive runs opposite to yours. The platform earns when compute and tokens spin, so it has no reason to make that layer cheaper for you.
And the lock-in there costs far more than the extra compute everyone expects. You also pay token spend on their meter that you cannot optimize away, because you do not control the layer. You pay a redefinition tax, settling your key metrics once per platform and then paying forever to reconcile the drift. You inherit model lock, because their agent runtime is tuned to their own AI. You lose negotiating leverage at renewal, because your meaning is hostage and you cannot credibly threaten to leave. You get governance fragmentation, with lineage and access enforced differently in each house. And you feel data gravity, because once your meaning lives there you are pulled to move more data and more workloads in to keep it coherent, which tightens the lock every quarter. If you ever do try to leave, you rebuild the entire semantic and ontology asset from scratch.
The third place is an independent layer that you own. Defined once, sitting across every source, readable by any model, and built for efficiency because efficiency is the only thing it sells. That is the one option where your meaning travels, your governance stays consistent, and you keep the leverage. It is not that the platforms build a bad dictionary. They build a very good one. They just build it inside a library that only opens for them.
You are paying on two meters, not one
This is the part I see most clearly from the value engineering seat, and the part that almost never makes it onto a keynote slide. When your meaning lives in their house, you pay on two meters at the same time.

Both meters run hot inside the platform. An independent layer slows both.
The first is the token meter. Every time an agent answers a question, it assembles the context at runtime, and that assembly burns tokens. A short question does not stay short. By the time the system has found the right tables, pulled the definitions, walked through a few reasoning steps, and called a tool or two, an eleven-word request has quietly become thousands of tokens, sometimes tens of thousands. Gartner estimates that an agentic task burns somewhere between five and thirty times the tokens of a simple chatbot reply. Per-token prices keep falling, which sounds like relief and is not, because the volume is climbing far faster than the price is dropping. I have watched a team's monthly AI spend go from a rounding error to a number the finance leader circles in red. One engineering organization reportedly burned through its entire annual AI budget in four months once coding agents caught on. There are documented cases of a single autonomous run racking up thousands of dollars in tokens before it produced anything useful.
The second is the platform meter. Every one of those context lookups also fires a query on their engine, on their compute, billed their way. So one business question spins two meters at once, and both of them belong to the platform.
Here is where independence changes the math, and changes it twice. Hand a model a clean, governed set of definitions instead of a pile of raw tables to interpret, and it reads less, guesses less, and loops less. In practice that is roughly half the tokens for a typical question, and with an agent architecture that answers straight from the governed layer instead of re-reasoning from scratch every time, token deflection can climb as high as ninety-eight percent. That is the token meter slowing down. At the same time, an independent layer caches the common answers, pre-builds the heavy aggregations, and pushes only the smallest necessary query down to the warehouse, so far fewer queries actually hit your compute. That is the platform meter slowing down too. And because your meaning is not trapped in one house, you keep your negotiating leverage at renewal instead of paying whatever the meter happens to read.
The logic underneath all of it is simple and worth stating bluntly. A platform earns money when the meter spins. It has no reason on earth to help you spin it less. An independent layer earns nothing when the meter spins. It only wins when your meters slow down, so making them slow down is the entire job. Those are not equivalent incentives, and you feel the difference on every invoice.
And you funded the thing that locks you in
There is one more turn of the screw, and it is the detail that should make a finance leader put the pen down. That context the platform built for you, so helpfully and automatically out of your own data, you paid for it. Every bit of it was assembled on your token meter and your compute meter. The single most valuable and least portable asset you now own, the one thing that would cost the most to rebuild anywhere else, you funded its construction inside someone else's control plane. You did not just accept the lock-in. You paid to build it, by the token, and you will keep paying to maintain it.
The honest other side, because there is one
I am not going to pretend a single platform is always the wrong answer, because it is not, and you should distrust anyone who tells you otherwise. For plenty of companies, keeping everything in one house is exactly right. You move less data. You pay fewer egress bills. You secure fewer copies. You govern one system instead of stitching five together, and you get to value faster because there is simply less to coordinate. If you are genuinely a single-platform company and you fully intend to stay one, take the native context layer and do not look back. It will be the fastest path you have.
The mistake is not choosing a platform. The mistake is pouring your business meaning into one without realizing you just made the most expensive and least reversible architectural decision of the decade, and without ever asking for a way back out.
And here is the inconvenient fact that applies to most large enterprises: you are not a single-platform shop, whatever the architecture diagram on the wall claims. The buyers' surveys keep finding the same pattern, that a clear majority of Databricks accounts also run Snowflake, a large share of Snowflake accounts also run Databricks, and nearly all of them have SAP and Oracle somewhere underneath, plus a long tail of older systems no one wants to touch. If that is your reality, a context layer that only works inside one of those houses does not solve your problem at all. It relocates the problem, and it charges you for the move.
What I would actually put on the table
Not as a pitch. As the questions I would ask if I were sitting on your side of the table.
Treat context as a contract term, not a feature. Before you deepen any single-platform context investment, get the answer in writing. Can you export the semantic models, the glossary, the ontology, and the lineage in an open, portable format, and who owns the context the platform auto-generates from your data. If moving your meaning to another platform would take more than a quarter, you are locked in, and you should price that into the deal the way you once priced egress.
Open the data, hedge the meaning. Standardizing the data layer on open formats is low risk, so do it now. But keep the authoritative version of your most important definitions, what revenue means, what a customer is, in a layer that does not belong to any single platform, and let each platform's native context enrich those definitions rather than own them.
Instrument the bill before you scale agents, not after. Model your token cost per workflow, not per chatbot, because the agentic multiplier is the thing that turns a pilot into a budget crisis. Put hard spend caps and cost-per-outcome reporting in place before a fleet of agents is loose on your data.
Make the consolidation call on purpose. Decide deliberately whether you are a one-platform company or a multi-platform one, and choose your context strategy to match. Either answer can be correct. Drifting into one by accident is the only answer that is wrong.
Fund the human part. Budget for the stewards and the cross-functional group that settles which number is official, because the automation will carry you most of the way and then stop exactly at the hard part. Assuming the machine will make that call for you is how you end up with a confident agent and a wrong answer.
The question that cuts through all of it
The vendors have placed their bets, and the announcements are just them turning their cards face up. The convergence is the real signal in all the noise. This is not one company's gamble you can wait out. It is the shape of the category now, and the decision is already in front of you whether anyone framed it for you or not.
So before you sign anything, make every platform answer one question in plain language. Where does my business meaning live, who pays to build it, and can I take it with me when I leave. If the answer is clean, wonderful. If it is not, you are not buying a platform. You are buying a switching cost with a very good user interface.
The lock-in moved to the context layer while everyone was busy admiring the agents. The leaders who notice first, and who keep their meaning in their own hands, are the ones who will still have leverage when the bill comes due.
SOURCES
Accuracy figures
Snowflake (23% / 47% / 83%, Cortex Sense in private preview): Snowflake CoWork: The Personal Work Agent for Every Knowledge Worker, Snowflake blog, June 2026. https://www.snowflake.com/en/blog/snowflake-cowork-personal-work-agent/
Databricks (52.4% vs 84.5% with Genie Ontology, internal 28-question benchmark): Introducing Genie One, Genie Agents, and Genie Ontology, Databricks blog, June 2026. https://www.databricks.com/blog/introducing-genie-one-genie-ontology-and-genie-agents
Market and cost figures
95% of enterprise GenAI pilots show no measurable P&L return: The GenAI Divide: State of AI in Business 2025, MIT Project NANDA, July 2025. Coverage: https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/
Worldwide AI spending over $2.5 trillion in 2026: Gartner Forecasts Worldwide AI Spending to Grow 47% in 2026, May 19, 2026. https://www.gartner.com/en/newsroom/press-releases/2026-05-19-gartner-forecasts-worldwide-ai-spending-to-grow-47-percent-in-2026
Agentic tasks use 5 to 30 times the tokens of a chatbot: Gartner Predicts That by 2030, Performing Inference on an LLM With 1 Trillion Parameters Will Cost GenAI Providers Over 90% Less Than in 2025, March 25, 2026. https://www.gartner.com/en/newsroom/press-releases/2026-03-25-gartner-predicts-that-by-2030-performing-inference-on-an-llm-with-1-trillion-parameters-will-cost-genai-providers-over-90-percent-less-than-in-2025
Most large enterprises run both Snowflake and Databricks (roughly 60% of Databricks accounts also run Snowflake): ETR / theCUBE Research, 2024. https://siliconangle.com/2024/07/27/databricks-vs-snowflake-not-zero-sum-game/
Platform context products
AWS Context: Context intelligence for your data and AI agents at scale, AWS blog, June 2026. https://aws.amazon.com/blogs/machine-learning/context-intelligence-for-your-data-and-ai-agents-at-scale/
Microsoft Fabric IQ: What is Fabric IQ? Microsoft Learn. https://learn.microsoft.com/en-us/fabric/iq/overview

Asim Lilani
Asim Lilani, VP of Value Engineering at Strategy, helps high-growth B2B companies scale by embedding value across the full customer lifecycle. He’s led 1,000+ value assessments, influenced $1B+ in revenue, and builds value programs, tools, and narratives that drive measurable business impact.
Content:
- Everyone built the same thing in the same quarter
- Give the silo war its due, because we won it
- Moving the data is not the same as moving what it means
- How the platforms build your context
- The model was never the bottleneck
- What that context is actually made of
- The lock-in moved to the context layer
- So where should your context live?
- You are paying on two meters, not one
- And you funded the thing that locks you in
- The honest other side, because there is one
- What I would actually put on the table
- The question that cuts through all of it
- SOURCES
Related posts

Enterprise AI struggles when data lacks governance and business context. Learn why data governance for AI is the foundation of trustworthy, scalable AI.

Beata Socha
June 30, 2026

Discover why fragmented semantic logic stalls data teams. Learn how centralizing business definitions with Strategy cuts prep time and builds trusted analytics.
Beata Socha
June 29, 2026

Learn how to choose a vendor-agnostic semantic layer for enterprise data stacks in 2026. Explore key criteria for portability, governance, AI readiness, and scalable multi-cloud analytics.

Henry Guo
May 4, 2026

Strategy Software’s platform-agnostic semantic layer closes the Governance Gap, enforcing consistent business definitions across 200+ data sources and every AI agent, not just within one data platform.

Lauren O’Connor
April 15, 2026